CCTV News: On May 17, the reporter learned from the 2025 Data Security Development Conference that my country will cultivate and expand a number of upstream and downstream enterprises in the data factor industry chain. It is estimated that by 2030, the scale of my country's data industry will reach 7.5 trillion yuan.
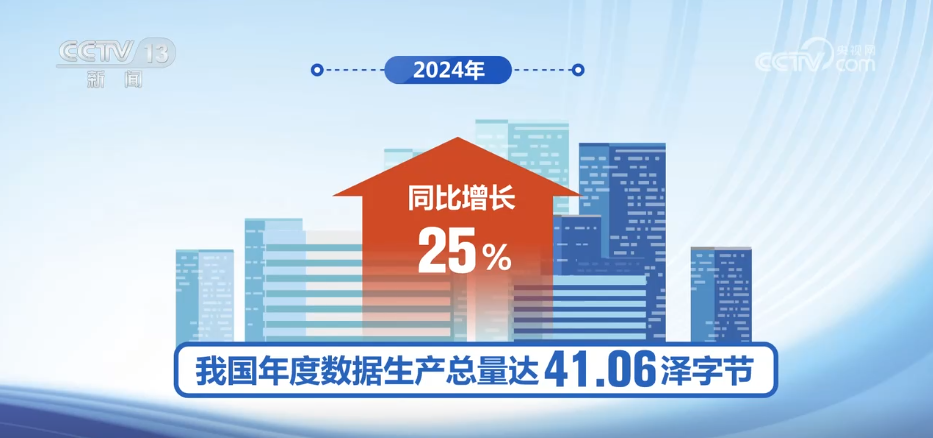
As the world's first country to include data into production factors, my country has initially built a complete data industry chain. Data shows that in 2024, my country's annual data production reached 41.06 zetes, a year-on-year increase of 25%. Up to now, there are more than 190,000 related companies in my country's data field, and the scale of the data industry exceeds 2 trillion yuan. Based on the annual growth rate of more than 20%, the scale of my country's data industry will reach 7.5 trillion yuan in 2030.

Liu Liehong, director of the National Data Administration, said that he is currently planning to build a horizontal, vertical, and coordinated and strong data infrastructure system, and basically build the main structure of the national data infrastructure by 2029.

Open sharing of public data has become an important breakthrough in the marketization of data elements. In 2024, the number of local public data open platforms at or above the municipal level nationwide increased by 7.5%, the number of open data increased by 7.1%, and the number of high-quality data sets increased by 27.4% year-on-year. In terms of the integration of data elements and industries, the country is accelerating the opening-up barriers to public data sharing, promoting the deep integration of public data and enterprise data, and activate a massive "sleeping data".
Constructing high-quality data sets to accelerate the development of artificial intelligence
At present, data has surpassed traditional production factors and has become the core driving force for breakthroughs in artificial intelligence technology and industrial transformation. High-quality data sets are not only the cornerstone of the leap in artificial intelligence model performance, but also reshape the entire industrial chain from technological research and development to commercial implementation. So how are high-quality data sets built?

In Wenzhou, Zhejiang, as a "test field" for the national market-oriented reform of data elements, a data security and compliance system has been built here to ensure the large-scale flow of data elements, form a data trading ecosystem, and make more data "live".
Technical personnel told reporters that building large model data sets mainly includes core links such as data collection, data cleaning, data annotation, and quality evaluation. Each link needs to carry out targeted technical research and development and adaptation based on the characteristics of the large-scale, sufficient diversity, and strong vertical attributes of the industry.
Data annotation and cleaning are key links in the construction of high-quality data sets. Data annotation teaches artificial intelligence to "cognize the world" by "labeling" (such as labeling "cats" and "dogs" for photos). Unlabeled data is like garbled textbooks, resulting in the inability of artificial intelligence to learn effectively; data cleaning purifies data by removing duplicates and correcting errors, and chaotic data will directly affect the effectiveness of artificial intelligence training.
The output value of my country's data labeling industry exceeds 8 billion
It can be seen that data labeling is a key link in the construction of high-quality data sets. So what is the development of my country's related industries? The "2025 High-Quality Data Set Research Report" released by the 2025 Data Security Development Conference shows that with the iteration of artificial intelligence and large-scale model technology, the output value of my country's data labeling industry has exceeded 8 billion yuan, and the construction of high-quality data has entered a new stage of large-scale and standardized development.
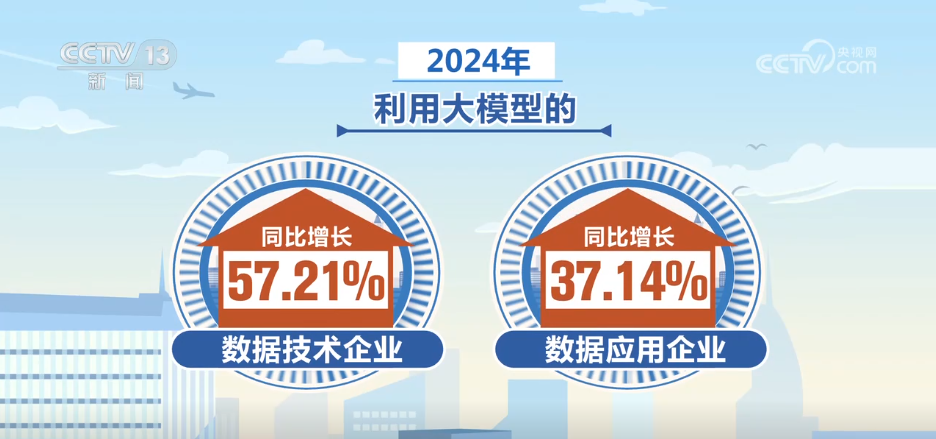
In 2024, the number of enterprises developing or applying artificial intelligence in my country increased by 36% year-on-year, and the number of high-quality data sets increased by 27.4% year-on-year, strongly supporting artificial intelligence training and application. Data technology companies using large models and data application companies increased by 57.21% and 37.14% year-on-year respectively.

The report shows that my country is currently accelerating the innovation and development of high-quality data sets, but it still faces problems such as small data stocks, low production, uneven quality of data sets, lack of mainstream high-value data guidance, and low data utilization efficiency.