CCTV 뉴스 : 5 월 17 일, 기자는 2025 년 데이터 보안 개발 회의에서 우리나라가 데이터 팩터 산업 체인에서 여러 상류 및 다운 스트림 기업을 배양하고 확장 할 것이라는 것을 알게되었습니다. 2030 년까지 우리 나라의 데이터 산업 규모는 7.5 조 위안에 도달 할 것으로 추정됩니다.

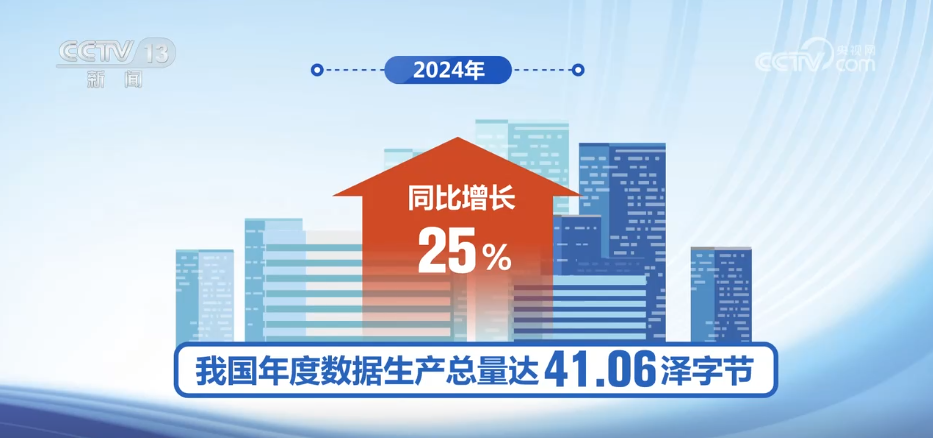
제 1 자국을 포함하여 내 국가는 초기에 처음으로 데이터를 포함 시켰습니다. 데이터에 따르면 2024 년에 우리 나라의 연간 데이터 생산은 41.06 Zetes에 이르렀으며 전년 대비 25%증가했습니다. 지금까지 우리나라의 데이터 분야에는 19 만 명 이상의 관련 회사가 있으며 데이터 산업의 규모는 2 조 위안을 초과합니다. 연간 성장률 20%이상을 기준으로, 우리 나라의 데이터 산업의 규모는 2030 년에 7.5 조 위안에 도달 할 것입니다.

국가 데이터 관리 이사 인 Liu Liehong은 현재 현재 수평, 수직 및 강력한 데이터 인프라 시스템을 구축 할 계획이며 기본적으로 2029 년까지 국가 데이터 인프라의 주요 구조를 구축 할 계획이라고 말했다. src = "http://www.china-news-online.com/pic/2025-05-18/1kqbamcvbsw.png"alt = ""//
공개 데이터의 공개 공유는 데이터 요소의 시장화에서 중요한 돌파구가되었습니다. 2024 년, 전국의 시정 수준 이상의 지역 공개 데이터 오픈 플랫폼의 수는 7.5%증가했으며, 개방형 데이터 수는 7.1%증가했으며, 고품질 데이터 세트의 수는 전년 대비 27.4%증가했습니다. 데이터 요소 및 산업의 통합 측면에서, 국가는 공개 데이터 공유에 대한 개방 장벽을 가속화하여 공개 데이터 및 엔터프라이즈 데이터의 깊은 통합을 촉진하고 대규모 "수면 데이터"를 활성화하고 있습니다.
인공 지능의 개발을 가속화하기 위해 고품질 데이터 세트 구성
현재 데이터는 전통적인 생산 요인을 능가했으며 인공 지능 기술과 산업 변화의 혁신적인 원동력이되었습니다. 고품질 데이터 세트는 인공 지능 모델 성능의 도약의 초석 일뿐 만 아니라 기술 연구 및 개발에서 상업적 구현에 이르기까지 전체 산업 체인을 재구성합니다. 그렇다면 고품질 데이터 세트는 어떻게 구축됩니까?

wenzhou in wenzhou, zhejong, a "test Field" 데이터 요소의 개혁, 데이터 보안 및 규정 준수 시스템은 데이터 요소의 대규모 흐름을 보장하고 데이터 거래 생태계를 형성하며 더 많은 데이터를 "라이브"로 만들기 위해 구축되었습니다.
기술 인력은 기자들에게 대규모 모델 데이터 세트를 구축에는 주로 데이터 수집, 데이터 정리, 데이터 주석 및 품질 평가와 같은 핵심 링크가 포함되어 있다고 말했습니다. 각 링크는 대규모, 충분한 다양성 및 업계의 강력한 수직 속성의 특성에 따라 목표 기술 연구 및 개발 및 적응을 수행해야합니다.
데이터 주석 및 청소는 고품질 데이터 세트를 구성 할 때 핵심 링크입니다. 데이터 주석은 인공 지능을 가르칩니다. "레이블링"(예 : 사진의 "고양이"및 "개"라는 표시 등)을 통해 "세계를 인식"하도록 가르칩니다. 표지되지 않은 데이터는 차별화 된 교과서와 같아서 인공 지능이 효과적으로 학습 할 수 없게됩니다. 데이터 청소는 중복을 제거하고 오류를 수정하여 데이터를 정화하며 혼란스러운 데이터는 인공 지능 교육의 효과에 직접적인 영향을 미칩니다.
우리 나라의 데이터 라벨링 산업의 출력 값은 80 억을 초과합니다
데이터 라벨링은 고품질 데이터 세트 구성의 핵심 링크임을 알 수 있습니다. 그렇다면 우리 나라의 관련 산업의 발전은 무엇입니까? 2025 년 데이터 보안 개발 컨퍼런스 (Data Security Development Conference)에서 발표 한 "2025 고품질 데이터 세트 리서치 보고서"는 인공 지능과 대규모 모델 기술의 반복에 따라 우리 나라의 데이터 라벨링 산업의 출력 가치가 80 억 위안을 초과했으며, 고품질 데이터의 건설은 대규모 대규모 스케일 및 표준화 된 개발의 새로운 단계에 들어갔다.
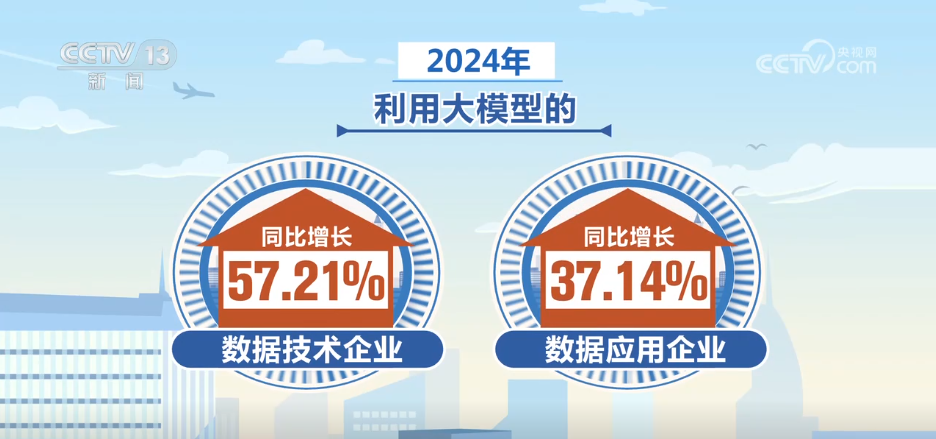 2024에서, Applyning Oppless On in Enterprese Or in Enterprese On의 수는 전년 대비 36%, 고품질 데이터 세트 수는 전년 대비 27.4% 증가하여 인공 지능 교육 및 응용 프로그램을 강력하게 지원했습니다. 대규모 모델 및 데이터 애플리케이션 회사를 사용하는 데이터 기술 회사는 각각 전년 대비 57.21% 및 37.14% 증가했습니다.
2024에서, Applyning Oppless On in Enterprese Or in Enterprese On의 수는 전년 대비 36%, 고품질 데이터 세트 수는 전년 대비 27.4% 증가하여 인공 지능 교육 및 응용 프로그램을 강력하게 지원했습니다. 대규모 모델 및 데이터 애플리케이션 회사를 사용하는 데이터 기술 회사는 각각 전년 대비 57.21% 및 37.14% 증가했습니다.

보고서는 현재 데이터가 혁신적이라는 것을 보여줍니다. 여전히 소규모 데이터 주식, 낮은 생산, 고르지 않은 데이터 세트 품질, 주류 고 부가가치 데이터 지침 부족 및 데이터 활용 효율이 낮은 문제에 직면 해 있습니다.