Le 17, le journaliste a appris de la conférence de développement de la sécurité des données de 2025 que mon pays cultivera et élargira un certain nombre d'entreprises en amont et en aval dans la chaîne de l'industrie du facteur de données. On estime qu'en 2030, l'ampleur de l'industrie des données de mon pays atteindra 7,5 billions de yuans.
Open partage des données publiques
Activer les "données de sommeil" massives
en tant que premier pays du monde à inclure des données dans les facteurs de production, mon pays a initialement construit une chaîne complète de l'industrie des données. Les données montrent que la production annuelle de données de mon pays en 2024 a atteint 41,06 octets ZET, soit une augmentation en glissement annuel de 25%.
Pour l'instant, il y a plus de 190 000 entreprises liées dans le domaine des données de mon pays, et l'échelle de l'industrie des données dépasse 2 billions de yuans. Sur la base du taux de croissance annuel de plus de 20%, l'ampleur de l'industrie des données de mon pays atteindra 7,5 billions de yuans en 2030.

Directeur de la National Data Administration Liu Liehong: À l'heure actuelle, nous prévoyons de construire un système d'infrastructure de données connecté, connecté verticalement et coordonné, et essentiellement la structure principale de l'infrastructure de données nationale d'ici 2029. src = "http://www.china-news-online.com/pic/2025-05-18/pudzsghxmjk.jpg" alt = "" //
Le partage ouvert des données publiques est devenu une percée importante sur le marché des éléments de données. En 2024, le nombre de plates-formes d'ouverture de données publiques locales au niveau municipal ou au-dessus du niveau municipal a augmenté de 7,5%, le nombre de données ouvertes a augmenté de 7,1% et le nombre d'ensembles de données de haute qualité a augmenté de 27,4% en glissement annuel.
En termes d'intégration des éléments de données et des industries, le pays accélère les obstacles d'ouverture au partage de données publics, promouvant l'intégration profonde des données publiques et des données d'entreprise et activent une "données de sommeil" massives.
Créer des ensembles de données de haute qualité
accélérer le développement de l'intelligence artificielle
à l'heure actuelle, les données ont dépassé les facteurs de production traditionnels et sont devenus la force motrice principale des percées dans la technologie de l'intelligence artificielle et la transformation industrielle. Les ensembles de données de haute qualité ne sont pas seulement la pierre angulaire du saut dans les performances du modèle d'intelligence artificielle, mais remodeler l'ensemble de la chaîne industrielle de la recherche et du développement technologiques à la mise en œuvre commerciale. Alors, comment les ensembles de données de haute qualité sont-ils construits?
Dans Wenzhou, Zhejiang, en tant que "champ de test" pour la réforme nationale des éléments de données, un système de sécurité et de conformité des données a été construit ici pour assurer le flux à grande échelle des éléments de données, former un écosystème de trading de données et rendre plus de données "en direct".

Jin Chuanla, directeur de l'abmiondance des données de la Donnée du Data Burreau de Wenzh, Jin Chuanla, Decuty Direct Province du Zhejiang: 469 "produits de données pratiques, faciles à utiliser et sûrs" ont été créés, et un lot d'ensembles de données de haute qualité a été construit dans les domaines des soins médicaux, du transport, de l'économie de basse altitude, etc.
Le personnel technique, a déclaré aux reporters que la création de grands ensembles de données de modèle comprend principalement des liens centraux tels que la collecte de données, le nettoyage des données, la rédaction des données et l'évaluation de la qualité. Chaque lien doit effectuer la recherche et le développement technologiques ciblés et l'adaptation en fonction des caractéristiques de la diversité à grande échelle, suffisante et des attributs verticaux forts de l'industrie.

Texte Huang Tiejun, école de sciences informatiques, Pékin: POUR DES TEMPS DE Texte, Huang Tiejun, École de sciences informatiques, Pékin: POUR DES TEMPS TEXT La littérature, les livres, les articles, les rapports de recherche, ont été utilisés. À l'avenir, plus de choses non textuelles sont encore nécessaires, comme les images, les vidéos et divers capteurs. Ces données sont également une source importante d'apprentissage du modèle à grande échelle.
L'annotation des données et le nettoyage sont des liens clés dans la construction d'ensembles de données de haute qualité.
L'annotation des données enseigne l'intelligence artificielle à "connaître le monde" à travers "l'étiquetage". Les données non marquées sont comme des manuels brouillés, ce qui entraîne l'intelligence artificielle incapable d'apprendre efficacement;
le nettoyage des données purifie les données en supprimant les doublons et la correction des erreurs, et les données chaotiques affecteront directement l'efficacité de la formation à l'intelligence artificielle.
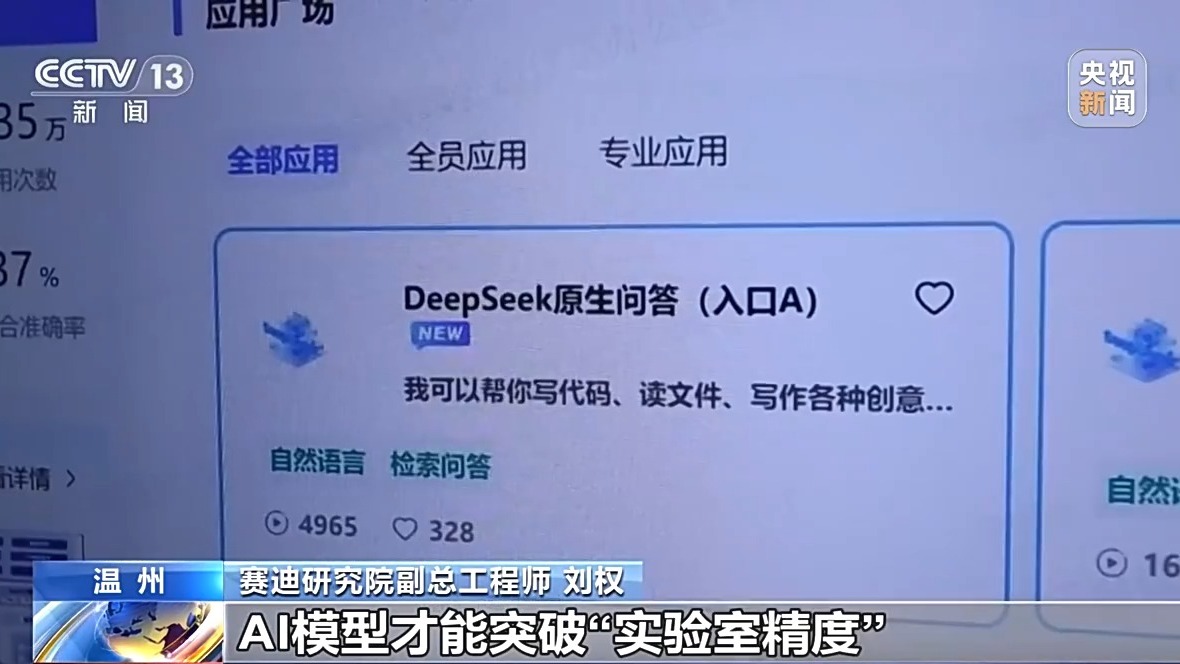
Liu Quan, Députy Chief Engineer of Cydie Institute When the Data Covers, Auty, ingénieur en chef du Cydie du Cydie Ingénieur de Cydie, When the Data Covers, AUVERS INSECTEUR DE DATATS, ENFECTÉE CHEFICATION DU CYDEAU CYDIE DU CYDIE CYDIE CYDICE CISTERNE: AUVERS AUS Un scénario suffisamment large et est marqué professionnellement que le modèle d'IA peut percer la «précision de laboratoire», a vraiment la capacité de mettre en œuvre des industries et de stimuler le développement de l'économie numérique.
The output value of my country's data labeling industry exceeds 8 billion yuan
The "2025 High-Quality Data Set Research Report" released at the 2025 Data Security Development Conference shows that with the iteration of artificial intelligence and large-scale model technology, the output value of my country's data labeling industry has exceeded 8 billion yuan, and the construction of high-quality data has entered a new stage of Développement à grande échelle et standardisé.
En 2024, le nombre d'entreprises développant ou appliquant l'intelligence artificielle dans mon pays a augmenté de 36% en glissement annuel, et le nombre d'ensembles de données de haute qualité a augmenté de 27,4% en glissement annuel, soutenant fortement la formation et l'application de l'intelligence artificielle. Les sociétés de technologie de données utilisant de grands modèles et des sociétés d'applications de données ont augmenté de 57,21% et 37,14% en glissement annuel respectivement.
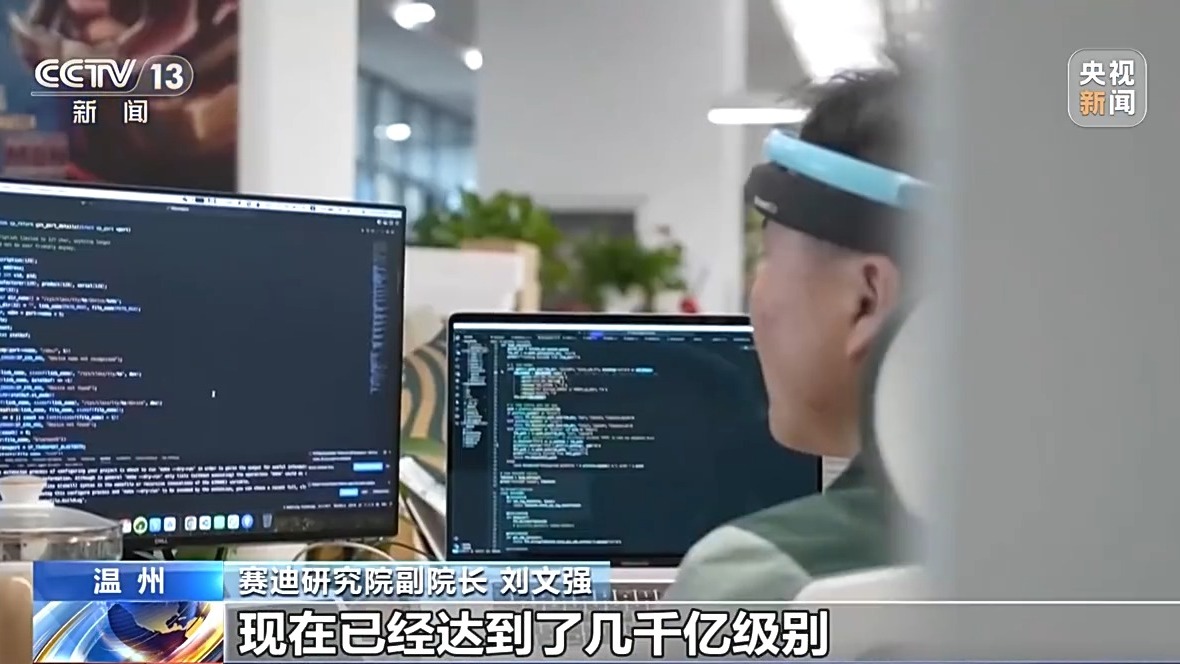
liu wenqiang, vice-président de la recherche cyclable: les principaux instituts de la recherche de la recherche: les principaux instituts de la recherche de la recherche: le vice-président de la recherche: les paradis de la Big Wenqiang, vice-président de Cydie Research of: The Paraders of Our Model Wenqiang, vice-président de Cydie Research Institute: The Paradeters of Our Model Wenqiang, vice-président de la recherche Cydie. atteint des centaines de milliards de niveaux. Promouvoir la construction de sept bases d'étiquetage de données à travers le pays, construisez 335 ensembles de données de haute qualité dans les domaines des soins médicaux, de l'industrie, de l'éducation, etc., avec une échelle de marquage totale de 1,7 billion de tuberculose, soutenant la recherche et le développement de 121 grands modèles nationaux.
Le rapport montre que mon pays accélère actuellement l'innovation et le développement d'ensembles de données de haute qualité, mais il est toujours confronté à des problèmes tels que les petites stocks de données et les faibles résultats, la qualité inégale des ensembles de données, le manque de guidages de données à grande valeur et une faible efficacité d'utilisation des données.

liu quan, ingénieur principal de l'ingénieur de cydy et assurer la fiabilité et l'intégrité des sources de données. Renforcer les garanties de confidentialité et de sécurité des données et promouvoir la construction de capacités d'évaluation de la sécurité des ensembles de données.
(reporters CCTV Wang Shiyu, Zhang Wei, Tang Zhijian, Zhang Yan, Han Dong)