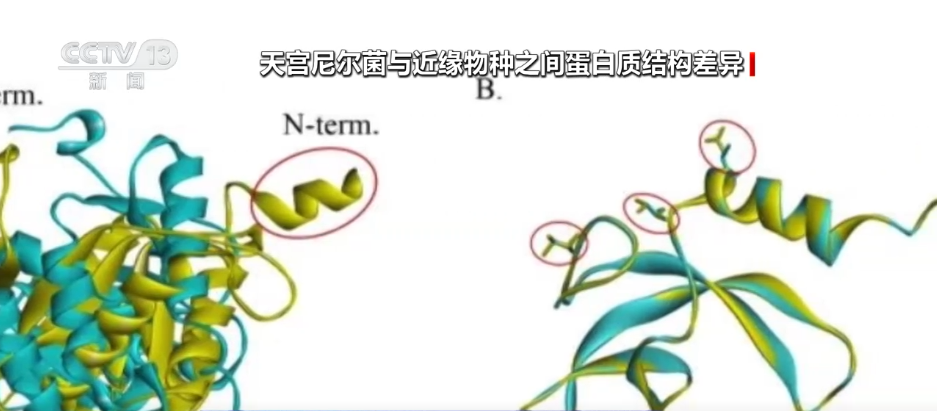
Il 17, il giornalista ha appreso dalla conferenza sullo sviluppo della sicurezza dei dati del 2025 che il mio paese coltizzerà ed espanderà una serie di imprese a monte e a valle nella catena del settore dei fattori dati. Si stima che entro il 2030 la portata dell'industria dei dati del mio paese raggiungerà 7,5 trilioni di yuan.
Condivisione aperta di dati pubblici
Attiva enormi "dati per dormire"
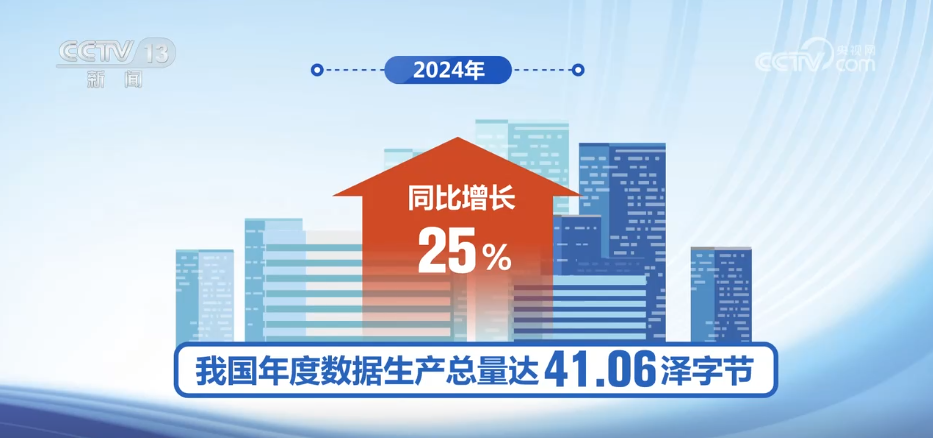
Come primo paese al mondo a includere i dati nei fattori di produzione, il mio paese ha inizialmente creato una catena completa del settore dei dati. I dati mostrano che la produzione annuale dei dati del mio paese nel 2024 ha raggiunto 41,06 byte Zet, un aumento di un anno in anno del 25%.
Al momento, ci sono più di 190.000 società correlate nel campo dei dati nel mio paese e la portata dell'industria dei dati supera i 2 trilioni di yuan. Sulla base del tasso di crescita annuale di oltre il 20%, la portata dell'industria dei dati del mio paese raggiungerà i 7,5 trilioni di yuan nel 2030.
Direttore della National Data Administration Liu Liehong: Attualmente, stiamo pianificando di costruire un sistema di infrastruttura dati coordinato in orizzontale, connesso verticalmente src = "http://www.china-news-online.com/pic/2025-05-18/pudzsghxmjk.jpg" alt = "" //
La condivisione aperta dei dati pubblici è diventata una svolta importante nella commercializzazione degli elementi dei dati. Nel 2024, il numero di piattaforme aperte di dati pubblici locali a livello municipale a livello nazionale è aumentato del 7,5%, il numero di dati aperti è aumentato del 7,1%e il numero di set di dati di alta qualità è aumentato del 27,4%su base annua.
In termini di integrazione di elementi e industrie di dati, il paese sta accelerando le barriere di apertura alla condivisione dei dati pubblici, promuovendo la profonda integrazione dei dati pubblici e dei dati aziendali e attiva un enorme "dati di sonno".
Costruisci set di dati di alta qualità
Accelera lo sviluppo dell'intelligenza artificiale
Al momento, i dati hanno superato i tradizionali fattori di produzione ed è diventato la forza trainante di base per le scoperte della tecnologia di intelligenza artificiale e la trasformazione industriale. I set di dati di alta qualità non sono solo la pietra angolare del salto nelle prestazioni del modello di intelligenza artificiale, ma rimodellano anche l'intera catena industriale dalla ricerca tecnologica e dallo sviluppo all'implementazione commerciale. Quindi, come vengono creati set di dati di alta qualità?
In Wenzhou, Zhejiang, come "campo di prova" per la riforma nazionale orientata al mercato degli elementi di dati, è stato creato un sistema di sicurezza e conformità dei dati per garantire il flusso su larga scala di elementi di dati, formare un ecosistema di negoziazione di dati e rendere più dati ".

Il personale tecnico ha detto ai giornalisti che costruendo set di dati di grandi dimensioni comprendono principalmente collegamenti fondamentali come raccolta dei dati, l'anno di pulizia dei dati. Ogni collegamento deve effettuare la ricerca, lo sviluppo e l'adattamento della tecnologia mirati in base alle caratteristiche della diversità sufficiente, sufficiente e ai forti attributi verticali del settore.

Professore Huang Huang, Scuola di Informatica, Most per i dati di TEXT, per i dati di TEXT, per la scienza di text, per la scienza di text, per la scienza di texy per text, Libri, articoli, rapporti di ricerca, sono stati utilizzati. In futuro, sono ancora necessarie cose più non testuali, come immagini, video e vari sensori. Questi dati sono anche un'importante fonte di apprendimento modello su larga scala.
L'annotazione e la pulizia dei dati sono collegamenti chiave nella costruzione di set di dati di alta qualità.
L'annotazione dei dati insegna all'intelligenza artificiale a "conoscere il mondo" attraverso "etichettatura". I dati senza etichetta sono come libri di testo confusi, con conseguente intelligenza artificiale che non è in grado di apprendere in modo efficace;
pulizia dei dati purifica i dati rimuovendo i duplicati e correggendo gli errori e i dati caotici influenzeranno direttamente l'efficacia dell'addestramento dell'intelligenza artificiale.
Liu Quan, deputy chief engineer of Cydie Research Institute: Only when the data covers a wide enough Lo scenario ed è marcato professionalmente può sfondare il modello di intelligenza artificiale attraverso la "precisione di laboratorio", avere davvero la capacità di attuare industrie e guidare lo sviluppo dell'economia digitale.
Il valore di output dell'industria dell'etichettatura dei dati del mio paese supera 8 miliardi di yuan
Il "Rapporto di ricerca sul set di dati di alta qualità 2025" rilasciato alla conferenza sullo sviluppo della sicurezza dei dati del 2025 mostra che con l'iterazione di dati artificiali di alta qualità e la costruzione di una fase di trasmissione artificiale ha una nuova fase di bonifica e la costruzione di una fase di bimasia e la costruzione di una fase di autodidatta e la costruzione di una fase di autodidatta ha una nuova fase di trasmissione e la costruzione di dati emersi in modo su larga scala su larga scala su larga scala su larga scala su larga scala su larga scala su larga scala su larga scala su vasta scala, la produzione di una fase di autodidatta ha una nuova fase di auto-lavanza e la costruzione di una fase di autodidatta e la costruzione di una fase di autodidatta e la costruzione di una fase di biga Sviluppo su larga scala e standardizzato.
Nel 2024, il numero di imprese che sviluppano o applicano l'intelligenza artificiale nel mio paese è aumentato del 36% su base annua e il numero di set di dati di alta qualità è aumentato del 27,4% su base annua, sostenendo fortemente la formazione e l'applicazione di intelligenza artificiale. Le società di tecnologia dei dati che utilizzano grandi modelli e società di applicazioni di dati sono aumentate rispettivamente del 57,21% e del 37,14% su base annua.
Liu Wenqiang, Vice President of Cydie Research Institute: The parameters of our big model have ha raggiunto centinaia di miliardi di livelli. Promuovere la costruzione di sette basi di etichettatura dei dati in tutto il paese, costruire 335 set di dati di alta qualità nei settori delle cure mediche, dell'industria, dell'istruzione, ecc.
Il rapporto mostra che il mio paese sta attualmente accelerando l'innovazione e lo sviluppo di set di dati di alta qualità, ma affronta ancora problemi come piccoli titoli di dati e bassi output, qualità irregolare dei set di dati, mancanza di orientamento dei dati di alto valore mainstream e bassa efficienza di utilizzo dei dati.

liu quan, depouty capo istituto di cydi a una buona ricerca di cydi a un buon lavoro: dà un buon lavoro di cydi a un buon lavoro: dà un buon lavoro di cydi a dati di lavoro di una ricerca su dati: dottogo-istituzione di un buon lavoro: fare un buon lavoro di cydi a dati di lavoro di dati di lavoro di cydi a Data. L'affidabilità e l'integrità delle fonti di dati. Rafforzare le garanzie sulla privacy e sulla sicurezza dei dati e promuovi la costruzione delle capacità di valutazione della sicurezza dei set di dati.
(Reporter CCTV Wang Shiyu, Zhang Wei, Tang Zhijian, Zhang Yan, Han Dong)